3.7 KiB
| label | order | icon |
|---|---|---|
| Finding video links | 995 | codescan |
Finding video links
Now you know the basics, enough to scrape most stuff from most sites, but not streaming sites.
Because of the high costs of video hosting the video providers really don't want anyone scraping the video and bypassing the ads.
This is why they often obfuscate, encrypt and hide their links which makes scraping really hard.
Some sites even put V3 Google Captcha on their links to prevent scraping while the majority IP/time/referer lock the video links to prevent sharing.
You will almost never find a plain <video> element with a mp4 link.
This is why you should always scrape the video first when trying to scrape a video hosting site. Sometimes getting the video link can be too hard.
I will therefore explain how to do more advanced scraping, how to get these video links.
What you want to do is:
- Find the iFrame/Video host.*
- Open the iFrame in a separate tab to ease clutter.*
- Find the video link.
- Work backwards from the video link to find the source.
- Step 1 and 2 is not applicable to all sites.
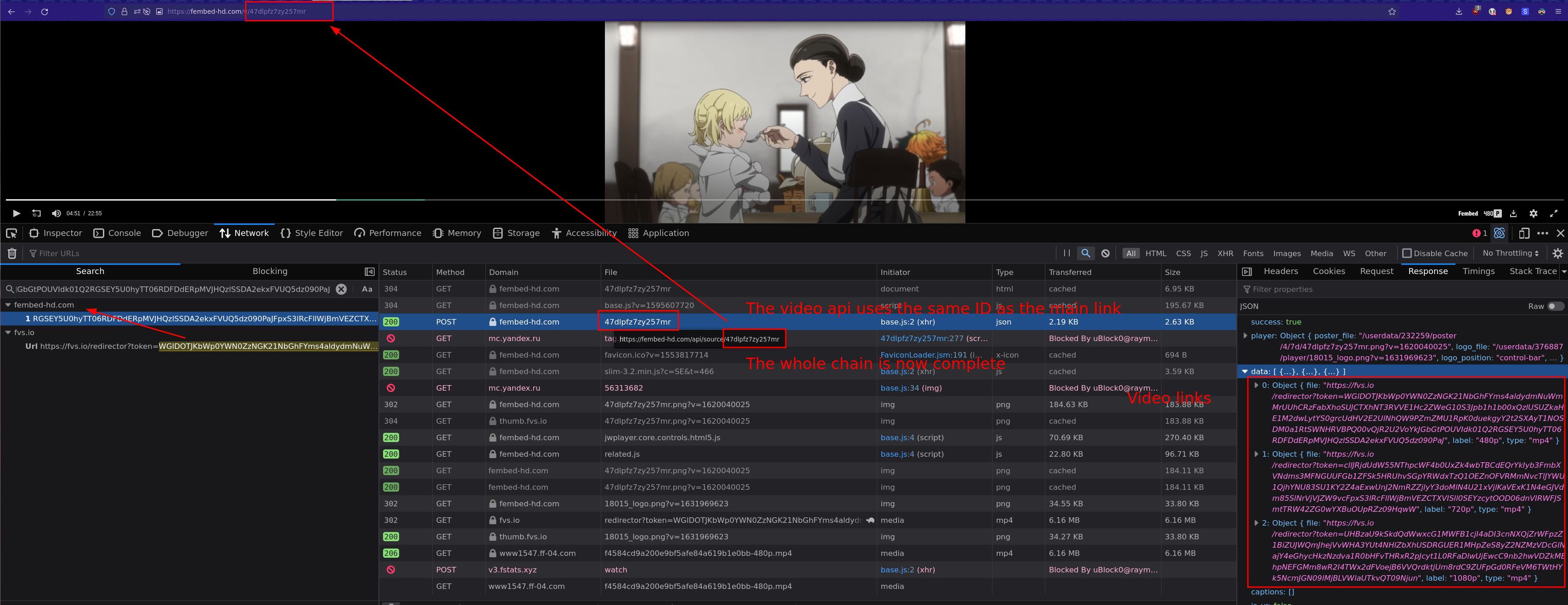
Let's explain further: Step 1: Most sites use an iFrame system to show their videos. This is essentially loading a separate page within the page. This is most evident in Gogoanime, link gets updated often, google the name and find their page if link isn't found. The easiest way of spotting these iframes is looking at the network tab trying to find requests not from the original site. I recommend using the HTML filter.

Once you have found the iFrame, in this case a fembed-hd link open it in another tab and work from there. (Step 2) If you only have the iFrame it is much easier to find the necessary stuff to generate the link since a lot of useless stuff from the original site is filtered out.
Step 3: Find the video link. This is often quite easy, either filter all media requests or simply look for a request ending in .m3u8 or .mp4 What this allows you to do is limit exclude many requests (only look at the requests before the video link) and start looking for the link origin (Step 4).

I usually search for stuff in the video link and see if any text/headers from the preceding requests contain it. In this case fvs.io redirected to the mp4 link, now do the same steps for the fvs.io link to follow the request backwards to the origin. Like images are showing.


NOTE: Some sites use encrypted JS to generate the video links. You need to use the browser debugger to step by step find how the links are generated in that case
What to do when the site uses a captcha?
You pretty much only have 3 options when that happens:
- Try to use a fake / no captcha token. Some sites actually doesn't check that the captcha token is valid.
- Use Webview or some kind of browser in the background to load the site in your stead.
- Pray it's a captcha without payload, then it's possible to get the captcha key without a browser: Code example