mirror of
https://github.com/recloudstream/website.git
synced 2024-08-15 03:18:45 +00:00
move docs to the new thing
This commit is contained in:
parent
557519e501
commit
7b6c4c4314
20 changed files with 23 additions and 1602 deletions
|
|
@ -1,26 +0,0 @@
|
||||||
---
|
|
||||||
title: Creating your own JSON repository
|
|
||||||
parent: For extension developers
|
|
||||||
order: 4
|
|
||||||
---
|
|
||||||
|
|
||||||
# Creating your own JSON repository
|
|
||||||
|
|
||||||
Cloudstream uses JSON files to fetch and parse lists of repositories. You can create one following this template:
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"name": "<repository name>",
|
|
||||||
"description": "<repository description>",
|
|
||||||
"manifestVersion": 1,
|
|
||||||
"pluginLists": [
|
|
||||||
"<direct link to plugins.json>"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
- `name`: self explanatory, will be visible in the app
|
|
||||||
- `description`: self explanatory, will be visible in the app
|
|
||||||
- `manifestVersion`: currently unused, may be used in the future for backwards compatibility
|
|
||||||
- `pluginLists`: List of urls, which contain plugins. All of them will be fetched.
|
|
||||||
- If you followed "[Using plugin template](../using-plugin-template.md)" tutorial, the appropriate `plugins.json` file should be in the builds branch of your new repository.
|
|
||||||
- If not, you can still generate one by running `gradlew makePluginsJson`
|
|
||||||
|
|
@ -1,301 +0,0 @@
|
||||||
---
|
|
||||||
title: Creating your own providers
|
|
||||||
parent: For extension developers
|
|
||||||
order: 2
|
|
||||||
---
|
|
||||||
|
|
||||||
# Creating your own Providers
|
|
||||||
|
|
||||||
Providers in CloudStream consists primarily of 4 different parts:
|
|
||||||
|
|
||||||
- [Searching](https://recloudstream.github.io/dokka/app/com.lagradost.cloudstream3/-main-a-p-i/index.html#498495168%2FFunctions%2F492899073)
|
|
||||||
- [Loading the home page](https://recloudstream.github.io/dokka/app/com.lagradost.cloudstream3/-main-a-p-i/index.html#1356482668%2FFunctions%2F492899073)
|
|
||||||
- [Loading the show page](https://recloudstream.github.io/dokka/app/com.lagradost.cloudstream3/-main-a-p-i/index.html#1671784382%2FFunctions%2F492899073)
|
|
||||||
- [Loading the video links](https://recloudstream.github.io/dokka/app/com.lagradost.cloudstream3/-main-a-p-i/index.html#-930139416%2FFunctions%2F492899073)
|
|
||||||
|
|
||||||
When making a provider it is important that you are confident you can scrape the video links first!
|
|
||||||
Video links are often the most protected part of the website and if you cannot scrape them then the provider is useless.
|
|
||||||
|
|
||||||
## 0. Scraping
|
|
||||||
|
|
||||||
If you are unfamiliar with the concept of scraping, you should probably start by reading [this guide](../scraping/index.md) which should hopefuly familiarize you with this technique.
|
|
||||||
|
|
||||||
## 1. Searching
|
|
||||||
|
|
||||||
This one is probably the easiest, based on a query you should return a list of [SearchResponse](https://recloudstream.github.io/dokka/app/com.lagradost.cloudstream3/-search-response/index.html)
|
|
||||||
|
|
||||||
Scraping the search results is essentially just finding the search item elements on the site (red box) and looking in them to find name, url and poster url and put the data in a SearchResponse.
|
|
||||||
|
|
||||||
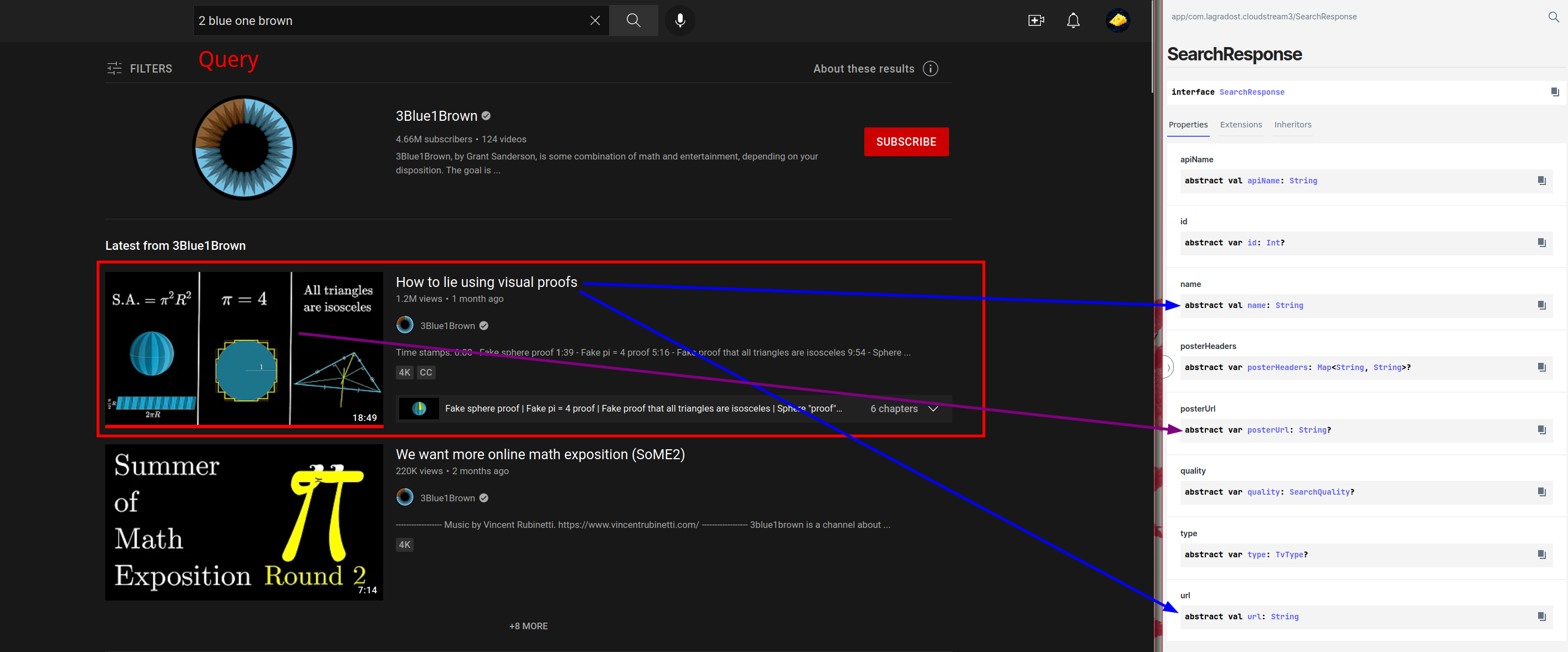
|
|
||||||
|
|
||||||
The code for the search then ideally looks something like
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
// (code for Eja.tv)
|
|
||||||
|
|
||||||
override suspend fun search(query: String): List<SearchResponse> {
|
|
||||||
return app.post(
|
|
||||||
mainUrl, data = mapOf("search" to query) // Fetch the search data
|
|
||||||
).document // Convert the response to a searchable document
|
|
||||||
.select("div.card-body") // Only select the search items using a CSS selector
|
|
||||||
.mapNotNull { // Convert all html elements to SearchResponses and filter out the null search results
|
|
||||||
it.toSearchResponse()
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// Converts a html element to a useable search response
|
|
||||||
// Basically just look in the element for sub-elements with the data you want
|
|
||||||
private fun Element.toSearchResponse(): LiveSearchResponse? {
|
|
||||||
// If no link element then it's no a valid search response
|
|
||||||
val link = this.select("div.alternative a").last() ?: return null
|
|
||||||
// fixUrl is a built in function to convert urls like /watch?v=..... to https://www.youtube.com/watch?v=.....
|
|
||||||
val href = fixUrl(link.attr("href"))
|
|
||||||
val img = this.selectFirst("div.thumb img")
|
|
||||||
// Optional parameter, scraping languages are not required but might be nice on some sites
|
|
||||||
val lang = this.selectFirst(".card-title > a")?.attr("href")?.removePrefix("?country=")
|
|
||||||
?.replace("int", "eu") //international -> European Union 🇪🇺
|
|
||||||
|
|
||||||
// There are many types of searchresponses but mostly you will be using AnimeSearchResponse, MovieSearchResponse
|
|
||||||
// and TvSeriesSearchResponse, all with different parameters (like episode count)
|
|
||||||
return LiveSearchResponse(
|
|
||||||
// Kinda hack way to get the title
|
|
||||||
img?.attr("alt")?.replaceFirst("Watch ", "") ?: return null,
|
|
||||||
href,
|
|
||||||
this@EjaTv.name,
|
|
||||||
TvType.Live,
|
|
||||||
fixUrl(img.attr("src")),
|
|
||||||
lang = lang
|
|
||||||
)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In this code snippet I have separated the Element to SearchResult conversion to a separate function because that function can often be used when scraping the home page later. No need to parse the same type of element twice.
|
|
||||||
|
|
||||||
## 2. Loading the home page
|
|
||||||
|
|
||||||
Getting the homepage is essentially the same as getting search results but with a twist: you define the queries in a variable like this:
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
|
|
||||||
override val mainPage = mainPageOf(
|
|
||||||
Pair("1", "Recent Release - Sub"),
|
|
||||||
Pair("2", "Recent Release - Dub"),
|
|
||||||
Pair("3", "Recent Release - Chinese"),
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
This dictates what the getMainPage function will be receiving as function arguments.
|
|
||||||
Basically when the recent dubbed shows should be loaded the getMainPage gets called with a page number and the request you defined above.
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
|
|
||||||
override suspend fun getMainPage(
|
|
||||||
page: Int,
|
|
||||||
request : MainPageRequest
|
|
||||||
): HomePageResponse {
|
|
||||||
|
|
||||||
// page: An integer > 0, starts on 1 and counts up, Depends on how much the user has scrolled.
|
|
||||||
// request.data == "2"
|
|
||||||
// request.name == "Recent Release - Dub"
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
With these variables you should fetch the appropriate list of Search Response like this:
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
|
|
||||||
// Gogoanime
|
|
||||||
override suspend fun getMainPage(
|
|
||||||
page: Int,
|
|
||||||
request : MainPageRequest
|
|
||||||
): HomePageResponse {
|
|
||||||
// Use the data you defined earlier in the pair to send the request you want.
|
|
||||||
val params = mapOf("page" to page.toString(), "type" to request.data)
|
|
||||||
val html = app.get(
|
|
||||||
"https://ajax.gogo-load.com/ajax/page-recent-release.html",
|
|
||||||
headers = headers,
|
|
||||||
params = params
|
|
||||||
)
|
|
||||||
val isSub = listOf(1, 3).contains(request.data.toInt())
|
|
||||||
|
|
||||||
// In this case a regex is used to get all the correct variables
|
|
||||||
// But if you defined the Element.toSearchResponse() earlier you can often times use it on the homepage
|
|
||||||
val home = parseRegex.findAll(html.text).map {
|
|
||||||
val (link, epNum, title, poster) = it.destructured
|
|
||||||
newAnimeSearchResponse(title, link) {
|
|
||||||
this.posterUrl = poster
|
|
||||||
addDubStatus(!isSub, epNum.toIntOrNull())
|
|
||||||
}
|
|
||||||
}.toList()
|
|
||||||
|
|
||||||
// Return a list of search responses mapped to the request name defined earlier.
|
|
||||||
return newHomePageResponse(request.name, home)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This might seem needlessly convoluted, but this system is to allow "infinite" loading, e.g loading the next page of search
|
|
||||||
responses when the user has scrolled to the end.
|
|
||||||
|
|
||||||
TLDR: Exactly like searching but you defined your own queries.
|
|
||||||
|
|
||||||
|
|
||||||
## 3. Loading the show page
|
|
||||||
|
|
||||||
// Currently Work in progress
|
|
||||||
|
|
||||||
The home page is a bit more complex than search results, but it uses the same logic used to get search results: using CSS selectors and regex to parse html into kotlin object. With the amount of info being parsed this function can get quite big, but the fundamentals are still pretty simple.
|
|
||||||
|
|
||||||
A function can look something like this:
|
|
||||||
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
|
|
||||||
// The url argument is the same as what you put in the Search Response from search() and getMainPage()
|
|
||||||
override suspend fun load(url: String): LoadResponse {
|
|
||||||
val document = app.get(url).document
|
|
||||||
|
|
||||||
val details = document.select("div.detail_page-watch")
|
|
||||||
val img = details.select("img.film-poster-img")
|
|
||||||
val posterUrl = img.attr("src")
|
|
||||||
// It's safe to throw errors here, they will be shown to the user and can help debugging.
|
|
||||||
val title = img.attr("title") ?: throw ErrorLoadingException("No Title")
|
|
||||||
|
|
||||||
var duration = document.selectFirst(".fs-item > .duration")?.text()?.trim()
|
|
||||||
var year: Int? = null
|
|
||||||
var tags: List<String>? = null
|
|
||||||
var cast: List<String>? = null
|
|
||||||
val youtubeTrailer = document.selectFirst("iframe#iframe-trailer")?.attr("data-src")
|
|
||||||
val rating = document.selectFirst(".fs-item > .imdb")?.text()?.trim()
|
|
||||||
?.removePrefix("IMDB:")?.toRatingInt()
|
|
||||||
|
|
||||||
// I would not really recommend
|
|
||||||
document.select("div.elements > .row > div > .row-line").forEach { element ->
|
|
||||||
val type = element?.select(".type")?.text() ?: return@forEach
|
|
||||||
when {
|
|
||||||
type.contains("Released") -> {
|
|
||||||
year = Regex("\\d+").find(
|
|
||||||
element.ownText() ?: return@forEach
|
|
||||||
)?.groupValues?.firstOrNull()?.toIntOrNull()
|
|
||||||
}
|
|
||||||
type.contains("Genre") -> {
|
|
||||||
tags = element.select("a").mapNotNull { it.text() }
|
|
||||||
}
|
|
||||||
type.contains("Cast") -> {
|
|
||||||
cast = element.select("a").mapNotNull { it.text() }
|
|
||||||
}
|
|
||||||
type.contains("Duration") -> {
|
|
||||||
duration = duration ?: element.ownText().trim()
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
val plot = details.select("div.description").text().replace("Overview:", "").trim()
|
|
||||||
|
|
||||||
val isMovie = url.contains("/movie/")
|
|
||||||
|
|
||||||
// https://sflix.to/movie/free-never-say-never-again-hd-18317 -> 18317
|
|
||||||
val idRegex = Regex(""".*-(\d+)""")
|
|
||||||
val dataId = details.attr("data-id")
|
|
||||||
val id = if (dataId.isNullOrEmpty())
|
|
||||||
idRegex.find(url)?.groupValues?.get(1)
|
|
||||||
?: throw ErrorLoadingException("Unable to get id from '$url'")
|
|
||||||
else dataId
|
|
||||||
|
|
||||||
val recommendations =
|
|
||||||
document.select("div.film_list-wrap > div.flw-item").mapNotNull { element ->
|
|
||||||
val titleHeader =
|
|
||||||
element.select("div.film-detail > .film-name > a") ?: return@mapNotNull null
|
|
||||||
val recUrl = fixUrlNull(titleHeader.attr("href")) ?: return@mapNotNull null
|
|
||||||
val recTitle = titleHeader.text() ?: return@mapNotNull null
|
|
||||||
val poster = element.select("div.film-poster > img").attr("data-src")
|
|
||||||
MovieSearchResponse(
|
|
||||||
recTitle,
|
|
||||||
recUrl,
|
|
||||||
this.name,
|
|
||||||
if (recUrl.contains("/movie/")) TvType.Movie else TvType.TvSeries,
|
|
||||||
poster,
|
|
||||||
year = null
|
|
||||||
)
|
|
||||||
}
|
|
||||||
|
|
||||||
if (isMovie) {
|
|
||||||
// Movies
|
|
||||||
val episodesUrl = "$mainUrl/ajax/movie/episodes/$id"
|
|
||||||
val episodes = app.get(episodesUrl).text
|
|
||||||
|
|
||||||
// Supported streams, they're identical
|
|
||||||
val sourceIds = Jsoup.parse(episodes).select("a").mapNotNull { element ->
|
|
||||||
var sourceId = element.attr("data-id")
|
|
||||||
if (sourceId.isNullOrEmpty())
|
|
||||||
sourceId = element.attr("data-linkid")
|
|
||||||
|
|
||||||
if (element.select("span").text().trim().isValidServer()) {
|
|
||||||
if (sourceId.isNullOrEmpty()) {
|
|
||||||
fixUrlNull(element.attr("href"))
|
|
||||||
} else {
|
|
||||||
"$url.$sourceId".replace("/movie/", "/watch-movie/")
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
null
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
val comingSoon = sourceIds.isEmpty()
|
|
||||||
|
|
||||||
return newMovieLoadResponse(title, url, TvType.Movie, sourceIds) {
|
|
||||||
this.year = year
|
|
||||||
this.posterUrl = posterUrl
|
|
||||||
this.plot = plot
|
|
||||||
addDuration(duration)
|
|
||||||
addActors(cast)
|
|
||||||
this.tags = tags
|
|
||||||
this.recommendations = recommendations
|
|
||||||
this.comingSoon = comingSoon
|
|
||||||
addTrailer(youtubeTrailer)
|
|
||||||
this.rating = rating
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
val seasonsDocument = app.get("$mainUrl/ajax/v2/tv/seasons/$id").document
|
|
||||||
val episodes = arrayListOf<Episode>()
|
|
||||||
var seasonItems = seasonsDocument.select("div.dropdown-menu.dropdown-menu-model > a")
|
|
||||||
if (seasonItems.isNullOrEmpty())
|
|
||||||
seasonItems = seasonsDocument.select("div.dropdown-menu > a.dropdown-item")
|
|
||||||
seasonItems.apmapIndexed { season, element ->
|
|
||||||
val seasonId = element.attr("data-id")
|
|
||||||
if (seasonId.isNullOrBlank()) return@apmapIndexed
|
|
||||||
|
|
||||||
var episode = 0
|
|
||||||
val seasonEpisodes = app.get("$mainUrl/ajax/v2/season/episodes/$seasonId").document
|
|
||||||
var seasonEpisodesItems =
|
|
||||||
seasonEpisodes.select("div.flw-item.film_single-item.episode-item.eps-item")
|
|
||||||
if (seasonEpisodesItems.isNullOrEmpty()) {
|
|
||||||
seasonEpisodesItems =
|
|
||||||
seasonEpisodes.select("ul > li > a")
|
|
||||||
}
|
|
||||||
seasonEpisodesItems.forEach {
|
|
||||||
val episodeImg = it?.select("img")
|
|
||||||
val episodeTitle = episodeImg?.attr("title") ?: it.ownText()
|
|
||||||
val episodePosterUrl = episodeImg?.attr("src")
|
|
||||||
val episodeData = it.attr("data-id") ?: return@forEach
|
|
||||||
|
|
||||||
episode++
|
|
||||||
|
|
||||||
val episodeNum =
|
|
||||||
(it.select("div.episode-number").text()
|
|
||||||
?: episodeTitle).let { str ->
|
|
||||||
Regex("""\d+""").find(str)?.groupValues?.firstOrNull()
|
|
||||||
?.toIntOrNull()
|
|
||||||
} ?: episode
|
|
||||||
|
|
||||||
episodes.add(
|
|
||||||
newEpisode(Pair(url, episodeData)) {
|
|
||||||
this.posterUrl = fixUrlNull(episodePosterUrl)
|
|
||||||
this.name = episodeTitle?.removePrefix("Episode $episodeNum: ")
|
|
||||||
this.season = season + 1
|
|
||||||
this.episode = episodeNum
|
|
||||||
}
|
|
||||||
)
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
# TODO: REST
|
|
||||||
|
|
@ -1,10 +0,0 @@
|
||||||
---
|
|
||||||
title: For extension developers
|
|
||||||
parent: null
|
|
||||||
order: 2
|
|
||||||
---
|
|
||||||
|
|
||||||
# For extension developers
|
|
||||||
This section will outline how to start developing your own extensions for Cloudstream.
|
|
||||||
|
|
||||||
You should probably start by reading [How to use our plugin template](../using-plugin-template.md).
|
|
||||||
|
|
@ -1,104 +0,0 @@
|
||||||
---
|
|
||||||
title: Devtools detector
|
|
||||||
parent: Scraping tutorial
|
|
||||||
order: 3
|
|
||||||
---
|
|
||||||
|
|
||||||
**TL;DR**: You are going to get fucked by sites detecting your devtools, the easiest bypass for this is using [a web sniffer extension](https://chrome.google.com/webstore/detail/web-sniffer/ndfgffclcpdbgghfgkmooklaendohaef?hl=en)
|
|
||||||
|
|
||||||
Many sites use some sort of debugger detection to prevent you from looking at the important requests made by the browser.
|
|
||||||
|
|
||||||
You can test the devtools detector [here](https://blog.aepkill.com/demos/devtools-detector/)
|
|
||||||
Code for the detector found [here](https://github.com/AEPKILL/devtools-detector)
|
|
||||||
|
|
||||||
# How are they detecting the tools?
|
|
||||||
|
|
||||||
One or more of the following methods are used to prevent devtools in the majority of cases (if not all):
|
|
||||||
|
|
||||||
**1.**
|
|
||||||
Calling `debugger` in an endless loop.
|
|
||||||
This is very easy to bypass. You can either right click the offending line (in chrome) and disable all debugger calls from that line or you can disable the whole debugger.
|
|
||||||
|
|
||||||
**2.**
|
|
||||||
Attaching a custom `.toString()` function to an expression and printing it with `console.log()`.
|
|
||||||
When devtools are open (even while not in console) all `console.log()` calls will be resloved and the custom `.toString()` function will be called. Functions can also be triggered by how dates, regex and functions are formatted in the console.
|
|
||||||
|
|
||||||
This lets the site know the millisecond you bring up devtools. Doing `const console = null` and other js hacks have not worked for me (the console function gets cached by the detector).
|
|
||||||
|
|
||||||
If you can find the offending js responsible for the detection you can bypass it by redifining the function in violentmonkey, but I recommend against it since it's often hidden and obfuscated. The best way to bypass this issue is to re-compile firefox or chrome with a switch to disable the console.
|
|
||||||
|
|
||||||
**3.**
|
|
||||||
Running a `while (true) {}` loop when the debugger object is present? Looks something like this in the wild:
|
|
||||||
```js
|
|
||||||
function _0x39426c(e) {
|
|
||||||
function t(e) {
|
|
||||||
if ("string" == typeof e)
|
|
||||||
return function(e) {}
|
|
||||||
.constructor("while (true) {}").apply("counter");
|
|
||||||
1 !== ("" + e / e).length || e % 20 == 0 ? function() {
|
|
||||||
return !0;
|
|
||||||
}
|
|
||||||
.constructor("debugger").call("action") : function() {
|
|
||||||
return !1;
|
|
||||||
}
|
|
||||||
.constructor("debugger").apply("stateObject"),
|
|
||||||
t(++e);
|
|
||||||
}
|
|
||||||
try {
|
|
||||||
if (e)
|
|
||||||
return t;
|
|
||||||
t(0);
|
|
||||||
} catch (e) {}
|
|
||||||
}
|
|
||||||
setInterval(function() {
|
|
||||||
_0x39426c();
|
|
||||||
}, 4e3);
|
|
||||||
```
|
|
||||||
This function can be tracked down to this [script](https://github.com/javascript-obfuscator/javascript-obfuscator/blob/6de7c41c3f10f10c618da7cd96596e5c9362a25f/src/custom-code-helpers/debug-protection/templates/debug-protection-function/DebuggerTemplate.ts)
|
|
||||||
|
|
||||||
I do not actually know how this works, but the loop seems gets triggered in the presence of a debugger. Either way this instantly freezes the webpage in firefox and makes it very unresponsive in chrome and does not rely on `console.log()`. You could bypass this by doing `const _0x39426c = null` in violentmonkey, but this bypass is not doable with heavily obfuscated js.
|
|
||||||
|
|
||||||
# How to bypass the detection?
|
|
||||||
|
|
||||||
If you just want to see the network log that is possible with extensions, see [Web Sniffer](https://chrome.google.com/webstore/detail/web-sniffer/ndfgffclcpdbgghfgkmooklaendohaef?hl=en)
|
|
||||||
|
|
||||||
I tracked down the functions making devtools detection possible in the firefox source code and compiled a version which is undetectable by any of these tools.
|
|
||||||
|
|
||||||
- [Linux build](https://mega.nz/file/YSAESJzb#x036cCtphjj9kB-kP_EXReTTkF7L7xN8nKw6sQN7gig)
|
|
||||||
- [Windows build](https://mega.nz/file/ZWAURAyA#qCrJ1BBxTLONHSTdE_boXMhvId-r0rk_kuPJWrPDiwg)
|
|
||||||
- [Mac build](https://mega.nz/file/Df5CRJQS#azO61dpP0_xgR8k-MmHaU_ufBvbl8_DlYky46SNSI0s)
|
|
||||||
|
|
||||||
- about:config `devtools.console.bypass` disables the console which invalidates **method 2**.
|
|
||||||
- about:config `devtools.debugger.bypass` completely disables the debugger, useful to bypass **method 3**.
|
|
||||||
|
|
||||||
If you want to compile firefox yourself with these bypasses you can, using the line changes below in the described files.
|
|
||||||
|
|
||||||
**BUILD: 101.0a1 (2022-04-19)**
|
|
||||||
`./devtools/server/actors/thread.js`
|
|
||||||
At line 390
|
|
||||||
```js
|
|
||||||
attach(options) {
|
|
||||||
let devtoolsBypass = Services.prefs.getBoolPref("devtools.debugger.bypass", true);
|
|
||||||
if (devtoolsBypass)
|
|
||||||
return;
|
|
||||||
```
|
|
||||||
|
|
||||||
`./devtools/server/actors/webconsole/listeners/console-api.js`
|
|
||||||
At line 92
|
|
||||||
```js
|
|
||||||
observe(message, topic) {
|
|
||||||
let devtoolsBypass = Services.prefs.getBoolPref("devtools.console.bypass", true);
|
|
||||||
if (!this.handler || devtoolsBypass) {
|
|
||||||
return;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
`./browser/app/profile/firefox.js`
|
|
||||||
At line 23
|
|
||||||
|
|
||||||
```js
|
|
||||||
// Bypasses
|
|
||||||
pref("devtools.console.bypass", true);
|
|
||||||
pref("devtools.debugger.bypass", true);
|
|
||||||
```
|
|
||||||
|
|
||||||
### Next up: [Why your requests fail](../disguising_your_scraper.md)
|
|
||||||
|
|
@ -1,195 +0,0 @@
|
||||||
---
|
|
||||||
title: Disguishing your scrapers
|
|
||||||
parent: Scraping tutorial
|
|
||||||
order: 4
|
|
||||||
---
|
|
||||||
|
|
||||||
# Disguishing your scrapers
|
|
||||||
|
|
||||||
<p align="center">
|
|
||||||
If you're writing a <b>Selenium</b> scraper, be aware that your skill level doesn't match the minimum requirements for this page.
|
|
||||||
</p>
|
|
||||||
|
|
||||||
## Why is scraping not appreciated?
|
|
||||||
|
|
||||||
- It obliterates ads and hence, blocks the site revenue.
|
|
||||||
- It is more than usually used to spam the content serving networks, hence, affecting the server performance.
|
|
||||||
- It is more than usually also used to steal content off of a site and serve in other.
|
|
||||||
- Competent scrapers usually look for exploits on site. Among these, the open source scrapers may leak site exploits to a wider audience.
|
|
||||||
|
|
||||||
## Why do you need to disguise your scraper?
|
|
||||||
|
|
||||||
Like the above points suggest, scraping is a good act. There are mechanisms to actively kill scrapers and only allow the humans in. You will need to make your scraper's identity as narrow as possible to a browser's identity.
|
|
||||||
|
|
||||||
Some sites check the client using headers and on-site javascript challenges. This will result in invalid responses along the status code of 400-499.
|
|
||||||
|
|
||||||
*Keep in mind that there are sites that produce responses without giving out the appropriate status codes.*
|
|
||||||
|
|
||||||
## Custom Headers
|
|
||||||
|
|
||||||
Here are some headers you need to check for:
|
|
||||||
|
|
||||||
| Header | What's the purpose of this? | What should I change this to? |
|
|
||||||
| --- | --- | --- |
|
|
||||||
| `User-Agent` | Specifies your client's name along with the versions. | Probably the user-agent used by your browser. |
|
|
||||||
| `Referer` | Specifies which site referred the current site. | The url from which **you** obtained the scraping url. |
|
|
||||||
| `X-Requested-With` | Specifies what caused the request to that site. This is prominent in site's AJAX / API. | Usually: `XMLHttpRequest`, it may vary based on the site's JS |
|
|
||||||
| `Cookie` | Cookie required to access the site. | Whatever the cookie was when you accessed the site in your normal browser. |
|
|
||||||
| `Authorization` | Authorization tokens / credentials required for site access. | Correct authorization tokens or credentials for site access. |
|
|
||||||
|
|
||||||
Usage of correct headers will give you site content access given you can access it through your web browser.
|
|
||||||
|
|
||||||
**Keep in mind that this is only the fraction of what the possible headers can be.**
|
|
||||||
|
|
||||||
## Appropriate Libraries
|
|
||||||
|
|
||||||
In Python, `requests` and `httpx` have differences.
|
|
||||||
|
|
||||||
```py
|
|
||||||
>>> import requests, httpx
|
|
||||||
>>> requests.get("http://www.crunchyroll.com/", headers={"User-Agent": "justfoolingaround/1", "Referer": "https://example.com/"})
|
|
||||||
<Response [403]>
|
|
||||||
>>> httpx.get("http://www.crunchyroll.com/", headers={"User-Agent": "justfoolingaround/1", "Referer": "https://example.com/"})
|
|
||||||
<Response [200 OK]>
|
|
||||||
```
|
|
||||||
|
|
||||||
As we can see, the former response is a 403. This is a forbidden response and generally specifies that the content is not present. The latter however is a 200, OK response. In this response, content is available.
|
|
||||||
|
|
||||||
This is the result of varying internal mechanisms.
|
|
||||||
|
|
||||||
The only cons to `httpx` in this case might be the fact that it has fully encoded headers, whilst `requests` does not. This means header keys consisting of non-ASCII characters may not be able to bypass some sites.
|
|
||||||
|
|
||||||
## Response handling algorithms
|
|
||||||
|
|
||||||
A session class is an object available in many libraries. This thing is like a house for your outgoing requests and incoming responses. A well written library has a session class that even accounts for appropriate cookie handling. Meaning, if you ever send a request to a site you need not need to worry about the cookie of that site for the next site you visit.
|
|
||||||
|
|
||||||
No matter how cool session classes may be, at the end of the day, they are mere objects. That means, you, as a user can easily change what is within it. (This may require a high understanding of the library and the language.)
|
|
||||||
|
|
||||||
This is done through inheritance. You inherit a session class and modify whats within.
|
|
||||||
|
|
||||||
For example:
|
|
||||||
|
|
||||||
```py
|
|
||||||
class QuiteANoise(httpx.Client):
|
|
||||||
|
|
||||||
def request(self, *args, **kwargs):
|
|
||||||
print("Ooh, I got a request with arguments: {!r}, and keyword arguments: {!r}.".format(args, kwargs))
|
|
||||||
response = super().request(*args, **kwargs)
|
|
||||||
print("That request has a {!r}!".format(response))
|
|
||||||
return response
|
|
||||||
```
|
|
||||||
|
|
||||||
In the above inherited session, what we do is *quite noisy*. We announced a request that is about to be sent and a response that was just recieved.
|
|
||||||
|
|
||||||
`super`, in Python, allows you to get the class that the current class inherits.
|
|
||||||
|
|
||||||
Do not forget to return your `response`, else your program will be dumbfounded since nothing ever gets out of your request!
|
|
||||||
|
|
||||||
So, we're going to abuse this fancy technique to effectively bypass some hinderances.
|
|
||||||
|
|
||||||
Namely `hCaptcha`, `reCaptcha` and `Cloudflare`.
|
|
||||||
|
|
||||||
```py
|
|
||||||
"""
|
|
||||||
This code is completely hypothetical, you probably
|
|
||||||
do not have a hCaptcha, reCaptcha and a Cloudflare
|
|
||||||
bypass.
|
|
||||||
|
|
||||||
This code is a mere reference and may not suffice
|
|
||||||
your need.
|
|
||||||
"""
|
|
||||||
from . import hcaptcha
|
|
||||||
from . import grecaptcha
|
|
||||||
|
|
||||||
import httpx
|
|
||||||
|
|
||||||
class YourScraperSession(httpx.Client):
|
|
||||||
|
|
||||||
def request(self, *args, **kwargs):
|
|
||||||
|
|
||||||
response = super().request(*args, **kwargs)
|
|
||||||
|
|
||||||
if response.status_code >= 400:
|
|
||||||
|
|
||||||
if hcaptcha.has_cloudflare(response):
|
|
||||||
cloudflare_cookie = hcaptcha.cloudflare_clearance_jar(self, response, *args, **kwargs)
|
|
||||||
self.cookies.update(cloudflare_cookie)
|
|
||||||
return self.request(self, *args, **kwargs)
|
|
||||||
|
|
||||||
# Further methods to bypass something else.
|
|
||||||
return self.request(self, *args, **kwargs) # psssssst. RECURSIVE HELL, `return response` is safer
|
|
||||||
|
|
||||||
|
|
||||||
hcaptcha_sk, type_of = hcaptcha.deduce_sitekey(self, response)
|
|
||||||
|
|
||||||
if hcaptcha_sk:
|
|
||||||
if type_of == 'hsw':
|
|
||||||
token = hcaptcha.get_hsw_token(self, response, hcaptcha_sk)
|
|
||||||
else:
|
|
||||||
token = hcaptcha.get_hsl_token(self, response, hcaptcha_sk)
|
|
||||||
|
|
||||||
setattr(response, 'hcaptcha_token', token)
|
|
||||||
|
|
||||||
recaptcha_sk, type_of = grecaptcha.sitekey_on_site(self, response)
|
|
||||||
|
|
||||||
if recaptcha_sk:
|
|
||||||
if isinstance(type_of, int):
|
|
||||||
token = grecaptcha.recaptcha_solve(self, response, recaptcha_sk, v=type_of)
|
|
||||||
else:
|
|
||||||
token = type_of
|
|
||||||
|
|
||||||
setattr(response, 'grecaptcha_token', token)
|
|
||||||
|
|
||||||
return response
|
|
||||||
```
|
|
||||||
|
|
||||||
So, let's see what happens here.
|
|
||||||
|
|
||||||
Firstly, we check whether the response has a error or not. This is done by checking if the response's status code is **greater than or equal to** 400.
|
|
||||||
|
|
||||||
After this, we check if the site has Cloudflare, if the site has Cloudflare, we let the hypothetical function do its magic and give us the bypass cookies. Then after, we update our session class' cookie. Cookie vary across sites but in this case, our hypothetical function will take the session and make it so that the cookie only applies to that site url within and with the correct headers.
|
|
||||||
|
|
||||||
After a magical cloudflare bypass (people wish they have this, you will too, probably.), we call the overridden function `.request` again to ensure the response following this will be bypassed to. This is recursion.
|
|
||||||
|
|
||||||
If anything else is required, you should add your own code to execute bypasses so that your responses will be crisp and never error-filled.
|
|
||||||
|
|
||||||
Else, we just return the fresh `.request`.
|
|
||||||
|
|
||||||
Keep in mind that if you cannot bypass the 400~ error, your responses might end up in a permanent recursive hell, at least in the code above.
|
|
||||||
|
|
||||||
To not make your responses never return, you might want to return the non-bypassed response.
|
|
||||||
|
|
||||||
The next part mainly focuses on CAPTCHA bypasses and what we do is quite simple. A completed CAPTCHA *usually* returns a token.
|
|
||||||
|
|
||||||
Returning this token with the response is not a good idea as the entire return type will change. We use a sneaky little function here. Namely `setattr`. What this does is, it sets an attribute of an object.
|
|
||||||
|
|
||||||
The algorithm in easier terms is:
|
|
||||||
|
|
||||||
Task: Bypass a donkey check with your human.
|
|
||||||
|
|
||||||
- Yell "hee~haw". (Prove that you're a donkey, this is how the hypothetical functions work.)
|
|
||||||
- Be handed the ribbon. (In our case, this is the token.)
|
|
||||||
|
|
||||||
Now the problem is, the ribbon is not a human but still needs to come back. How does a normal human do this? Wear the ribbon.
|
|
||||||
|
|
||||||
Wearing the ribbon is `setattr`. We can wear the ribbon everywhere. Leg, foot, butt.. you name it. No matter where you put it, you get the ribbon, so just be a bit reasonable with it. Like a decent developer and a decent human, wear the ribbon on the left side of your chest. In the code above, this reasonable place is `<captcha_name>_token`.
|
|
||||||
|
|
||||||
Let's get out of this donkey business.
|
|
||||||
|
|
||||||
After this reasonable token placement, we get the response back.
|
|
||||||
|
|
||||||
This token can now, always be accessed in reasonable places, reasonably.
|
|
||||||
|
|
||||||
|
|
||||||
```py
|
|
||||||
client = YourScraperSession()
|
|
||||||
|
|
||||||
bypassed_response = client.get("https://kwik.cx/f/2oHQioeCvHtx")
|
|
||||||
print(bypassed_response.hcaptcha_token)
|
|
||||||
```
|
|
||||||
|
|
||||||
Keep in mind that if there is no ribbon/token, there is no way of reasonably accessing it.
|
|
||||||
|
|
||||||
In any case, this is how you, as a decent developer, handle the response properly.
|
|
||||||
|
|
||||||
### Next up: [Finding video links](../finding_video_links.md)
|
|
||||||
|
|
@ -1,67 +0,0 @@
|
||||||
---
|
|
||||||
title: Finding video links
|
|
||||||
parent: Scraping tutorial
|
|
||||||
order: 5
|
|
||||||
---
|
|
||||||
|
|
||||||
# Finding video links
|
|
||||||
|
|
||||||
Now you know the basics, enough to scrape most stuff from most sites, but not streaming sites.
|
|
||||||
Because of the high costs of video hosting the video providers really don't want anyone scraping the video and bypassing the ads.
|
|
||||||
This is why they often obfuscate, encrypt and hide their links which makes scraping really hard.
|
|
||||||
Some sites even put V3 Google Captcha on their links to prevent scraping while the majority IP/time/referer lock the video links to prevent sharing.
|
|
||||||
You will almost never find a plain `<video>` element with a mp4 link.
|
|
||||||
|
|
||||||
**This is why you should always scrape the video first when trying to scrape a video hosting site. Sometimes getting the video link can be too hard.**
|
|
||||||
|
|
||||||
I will therefore explain how to do more advanced scraping, how to get these video links.
|
|
||||||
|
|
||||||
What you want to do is:
|
|
||||||
|
|
||||||
1. Find the iFrame/Video host.*
|
|
||||||
2. Open the iFrame in a separate tab to ease clutter.*
|
|
||||||
3. Find the video link.
|
|
||||||
4. Work backwards from the video link to find the source.
|
|
||||||
|
|
||||||
* *Step 1 and 2 is not applicable to all sites.*
|
|
||||||
|
|
||||||
Let's explain further:
|
|
||||||
**Step 1**: Most sites use an iFrame system to show their videos. This is essentially loading a separate page within the page.
|
|
||||||
This is most evident in [Gogoanime](https://gogoanime.gg/yakusoku-no-neverland-episode-1), link gets updated often, google the name and find their page if link isn't found.
|
|
||||||
The easiest way of spotting these iframes is looking at the network tab trying to find requests not from the original site. I recommend using the HTML filter.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Once you have found the iFrame, in this case a fembed-hd link open it in another tab and work from there. (**Step 2**)
|
|
||||||
If you only have the iFrame it is much easier to find the necessary stuff to generate the link since a lot of useless stuff from the original site is filtered out.
|
|
||||||
|
|
||||||
**Step 3**: Find the video link. This is often quite easy, either filter all media requests or simply look for a request ending in .m3u8 or .mp4
|
|
||||||
What this allows you to do is limit exclude many requests (only look at the requests before the video link) and start looking for the link origin (**Step 4**).
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
I usually search for stuff in the video link and see if any text/headers from the preceding requests contain it.
|
|
||||||
In this case fvs.io redirected to the mp4 link, now do the same steps for the fvs.io link to follow the request backwards to the origin. Like images are showing.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
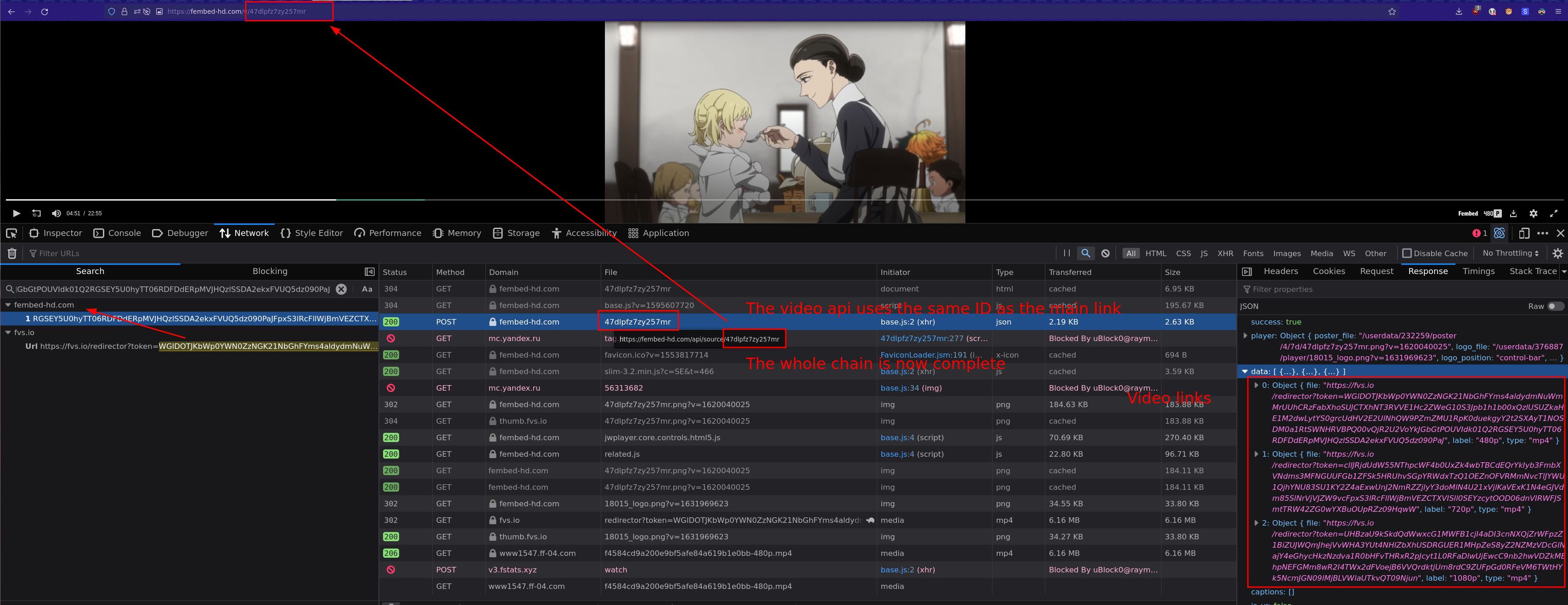
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**NOTE: Some sites use encrypted JS to generate the video links. You need to use the browser debugger to step by step find how the links are generated in that case**
|
|
||||||
|
|
||||||
## **What to do when the site uses a captcha?**
|
|
||||||
|
|
||||||
You pretty much only have 3 options when that happens:
|
|
||||||
|
|
||||||
1. Try to use a fake / no captcha token. Some sites actually doesn't check that the captcha token is valid.
|
|
||||||
2. Use Webview or some kind of browser in the background to load the site in your stead.
|
|
||||||
3. Pray it's a captcha without payload, then it's possible to get the captcha key without a browser: [Code example](https://github.com/recloudstream/cloudstream/blob/ccb38542f4b5685e511824a975bf16190011c222/app/src/main/java/com/lagradost/cloudstream3/MainAPI.kt#L132-L181)
|
|
||||||
|
|
@ -1,21 +0,0 @@
|
||||||
---
|
|
||||||
title: Scraping tutorial
|
|
||||||
parent: For extension developers
|
|
||||||
order: 3
|
|
||||||
---
|
|
||||||
|
|
||||||
# Requests based scraping tutorial
|
|
||||||
|
|
||||||
You want to start scraping? Well this guide will teach you, and not some baby selenium scraping. This guide only uses raw requests and has examples in both python and kotlin. Only basic programming knowlege in one of those languages is required to follow along in the guide.
|
|
||||||
|
|
||||||
If you find any aspect of this guide confusing please open an issue about it and I will try to improve things.
|
|
||||||
|
|
||||||
If you do not know programming at all then this guide will __not__ help you, learn programming! first Real scraping cannot be done by copy pasting with a vauge understanding.
|
|
||||||
|
|
||||||
0. [Starting scraping from zero](../starting.md)
|
|
||||||
1. [Properly scraping JSON apis often found on sites](../using_apis.md)
|
|
||||||
2. [Evading developer tools detection when scraping](../devtools_detectors.md)
|
|
||||||
3. [Why your requests fail and how to fix them](../disguising_your_scraper.md)
|
|
||||||
4. [Finding links and scraping videos](../finding_video_links.md)
|
|
||||||
|
|
||||||
Once you've read and understood the concepts behind scraping take a look at [a provider for CloudStream](https://github.com/recloudstream/cloudstream-extensions/blob/master/VidstreamBundle/src/main/kotlin/com/lagradost/VidEmbedProvider.kt#L4). I added tons of comments to make every aspect of writing CloudStream providers clear. Even if you're not planning on contributing to Cloudstream looking at the code may help.
|
|
||||||
|
|
@ -1,224 +0,0 @@
|
||||||
---
|
|
||||||
title: Starting
|
|
||||||
parent: Scraping tutorial
|
|
||||||
order: 1
|
|
||||||
---
|
|
||||||
|
|
||||||
Scraping is just downloading a webpage and getting the wanted information from it.
|
|
||||||
As a start you can scrape the README.md
|
|
||||||
|
|
||||||
|
|
||||||
I'll use khttp for the kotlin implementation because of the ease of use, if you want something company-tier I'd recommend OkHttp.
|
|
||||||
|
|
||||||
**Update**: I have made an okhttp wrapper **for android apps**, check out [NiceHttp](https://github.com/Blatzar/NiceHttp)
|
|
||||||
|
|
||||||
|
|
||||||
# **1. Scraping the Readme**
|
|
||||||
|
|
||||||
**Python**
|
|
||||||
```python
|
|
||||||
import requests
|
|
||||||
url = "https://recloudstream.github.io/devs/scraping/"
|
|
||||||
response = requests.get(url)
|
|
||||||
print(response.text) # Prints the readme
|
|
||||||
```
|
|
||||||
|
|
||||||
**Kotlin**
|
|
||||||
|
|
||||||
In build.gradle:
|
|
||||||
```gradle
|
|
||||||
repositories {
|
|
||||||
mavenCentral()
|
|
||||||
jcenter()
|
|
||||||
maven { url 'https://jitpack.io' }
|
|
||||||
}
|
|
||||||
|
|
||||||
dependencies {
|
|
||||||
// Other dependencies above
|
|
||||||
compile group: 'khttp', name: 'khttp', version: '1.0.0'
|
|
||||||
}
|
|
||||||
```
|
|
||||||
In main.kt
|
|
||||||
```kotlin
|
|
||||||
fun main() {
|
|
||||||
val url = "https://recloudstream.github.io/devs/scraping/"
|
|
||||||
val response = khttp.get(url)
|
|
||||||
println(response.text)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
# **2. Getting the github project description**
|
|
||||||
Scraping is all about getting what you want in a good format you can use to automate stuff.
|
|
||||||
|
|
||||||
Start by opening up the developer tools, using
|
|
||||||
|
|
||||||
<kbd>Ctrl</kbd> + <kbd>Shift</kbd> + <kbd>I</kbd>
|
|
||||||
|
|
||||||
or
|
|
||||||
|
|
||||||
<kbd>f12</kbd>
|
|
||||||
|
|
||||||
or
|
|
||||||
|
|
||||||
Right click and press *Inspect*
|
|
||||||
|
|
||||||
In here you can look at all the network requests the browser is making and much more, but the important part currently is the HTML displayed. You need to find the HTML responsible for showing the project description, but how?
|
|
||||||
|
|
||||||
Either click the small mouse in the top left of the developer tools or press
|
|
||||||
|
|
||||||
<kbd>Ctrl</kbd> + <kbd>Shift</kbd> + <kbd>C</kbd>
|
|
||||||
|
|
||||||
This makes your mouse highlight any element you hover over. Press the description to highlight up the element responsible for showing it.
|
|
||||||
|
|
||||||
Your HTML will now be focused on something like:
|
|
||||||
|
|
||||||
|
|
||||||
```html
|
|
||||||
<p class="f4 mt-3">
|
|
||||||
Work in progress tutorial for scraping streaming sites
|
|
||||||
</p>
|
|
||||||
```
|
|
||||||
|
|
||||||
Now there's multiple ways to get the text, but the 2 methods I always use is Regex and CSS selectors. Regex is basically a ctrl+f on steroids, you can search for anything. CSS selectors is a way to parse the HTML like a browser and select an element in it.
|
|
||||||
|
|
||||||
## CSS Selectors
|
|
||||||
|
|
||||||
The element is a paragraph tag, eg `<p>`, which can be found using the CSS selector: "p".
|
|
||||||
|
|
||||||
classes helps to narrow down the CSS selector search, in this case: `class="f4 mt-3"`
|
|
||||||
|
|
||||||
This can be represented with
|
|
||||||
```css
|
|
||||||
p.f4.mt-3
|
|
||||||
```
|
|
||||||
a dot for every class [full list of CSS selectors found here](https://www.w3schools.com/cssref/css_selectors.asp)
|
|
||||||
|
|
||||||
You can test if this CSS selector works by opening the console tab and typing:
|
|
||||||
|
|
||||||
```js
|
|
||||||
document.querySelectorAll("p.f4.mt-3");
|
|
||||||
```
|
|
||||||
|
|
||||||
This prints:
|
|
||||||
```java
|
|
||||||
NodeList [p.f4.mt-3]
|
|
||||||
```
|
|
||||||
|
|
||||||
### **NOTE**: You may not get the same results when scraping from command line, classes and elements are sometimes created by javascript on the site.
|
|
||||||
|
|
||||||
|
|
||||||
**Python**
|
|
||||||
|
|
||||||
```python
|
|
||||||
import requests
|
|
||||||
from bs4 import BeautifulSoup # Full documentation at https://www.crummy.com/software/BeautifulSoup/bs4/doc/
|
|
||||||
|
|
||||||
url = "https://github.com/Blatzar/scraping-tutorial"
|
|
||||||
response = requests.get(url)
|
|
||||||
soup = BeautifulSoup(response.text, 'lxml')
|
|
||||||
element = soup.select("p.f4.mt-3") # Using the CSS selector
|
|
||||||
print(element[0].text.strip()) # Selects the first element, gets the text and strips it (removes starting and ending spaces)
|
|
||||||
```
|
|
||||||
|
|
||||||
**Kotlin**
|
|
||||||
|
|
||||||
In build.gradle:
|
|
||||||
```gradle
|
|
||||||
repositories {
|
|
||||||
mavenCentral()
|
|
||||||
jcenter()
|
|
||||||
maven { url 'https://jitpack.io' }
|
|
||||||
}
|
|
||||||
|
|
||||||
dependencies {
|
|
||||||
// Other dependencies above
|
|
||||||
implementation "org.jsoup:jsoup:1.11.3"
|
|
||||||
compile group: 'khttp', name: 'khttp', version: '1.0.0'
|
|
||||||
}
|
|
||||||
```
|
|
||||||
In main.kt
|
|
||||||
```kotlin
|
|
||||||
fun main() {
|
|
||||||
val url = "https://github.com/Blatzar/scraping-tutorial"
|
|
||||||
val response = khttp.get(url)
|
|
||||||
val soup = Jsoup.parse(response.text)
|
|
||||||
val element = soup.select("p.f4.mt-3") // Using the CSS selector
|
|
||||||
println(element.text().trim()) // Gets the text and strips it (removes starting and ending spaces)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
## **Regex:**
|
|
||||||
|
|
||||||
When working with Regex I highly recommend using (regex101.com)[https://regex101.com/] (using the python flavor)
|
|
||||||
|
|
||||||
Press <kbd>Ctrl</kbd> + <kbd>U</kbd>
|
|
||||||
|
|
||||||
to get the whole site document as text and copy everything
|
|
||||||
|
|
||||||
Paste it in the test string in regex101 and try to write an expression to only capture the text you want.
|
|
||||||
|
|
||||||
In this case the elements is
|
|
||||||
|
|
||||||
```html
|
|
||||||
<p class="f4 mt-3">
|
|
||||||
Work in progress tutorial for scraping streaming sites
|
|
||||||
</p>
|
|
||||||
```
|
|
||||||
|
|
||||||
Maybe we can search for `<p class="f4 mt-3">` (backslashes for ")
|
|
||||||
|
|
||||||
```regex
|
|
||||||
<p class=\"f4 mt-3\">
|
|
||||||
```
|
|
||||||
|
|
||||||
Gives a match, so lets expand the match to all characters between the two brackets ( p>....</ )
|
|
||||||
Some important tokens for that would be:
|
|
||||||
|
|
||||||
- `.*?` to indicate everything except a newline any number of times, but take as little as possible
|
|
||||||
- `\s*` to indicate whitespaces except a newline any number of times
|
|
||||||
- `(*expression inside*)` to indicate groups
|
|
||||||
|
|
||||||
Which gives:
|
|
||||||
|
|
||||||
```regex
|
|
||||||
<p class=\"f4 mt-3\">\s*(.*)?\s*<
|
|
||||||
```
|
|
||||||
|
|
||||||
**Explained**:
|
|
||||||
|
|
||||||
Any text exactly matching `<p class="f4 mt-3">`
|
|
||||||
then any number of whitespaces
|
|
||||||
then any number of any characters (which will be stored in group 1)
|
|
||||||
then any number of whitespaces
|
|
||||||
then the text `<`
|
|
||||||
|
|
||||||
|
|
||||||
In code:
|
|
||||||
|
|
||||||
**Python**
|
|
||||||
|
|
||||||
```python
|
|
||||||
import requests
|
|
||||||
import re # regex
|
|
||||||
|
|
||||||
url = "https://github.com/Blatzar/scraping-tutorial"
|
|
||||||
response = requests.get(url)
|
|
||||||
description_regex = r"<p class=\"f4 mt-3\">\s*(.*)?\s*<" # r"" stands for raw, which makes blackslashes work better, used for regexes
|
|
||||||
description = re.search(description_regex, response.text).groups()[0]
|
|
||||||
print(description)
|
|
||||||
```
|
|
||||||
|
|
||||||
**Kotlin**
|
|
||||||
In main.kt
|
|
||||||
```kotlin
|
|
||||||
fun main() {
|
|
||||||
val url = "https://github.com/Blatzar/scraping-tutorial"
|
|
||||||
val response = khttp.get(url)
|
|
||||||
val descriptionRegex = Regex("""<p class="f4 mt-3">\s*(.*)?\s*<""")
|
|
||||||
val description = descriptionRegex.find(response.text)?.groups?.get(1)?.value
|
|
||||||
println(description)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
### Next up: [Properly scraping JSON apis](../using_apis.md)
|
|
||||||
|
|
@ -1,173 +0,0 @@
|
||||||
---
|
|
||||||
title: Using APIs
|
|
||||||
parent: Scraping tutorial
|
|
||||||
order: 2
|
|
||||||
---
|
|
||||||
|
|
||||||
### About
|
|
||||||
Whilst scraping a site is always a nice option, using it's API is way better. <br/>
|
|
||||||
And sometimes its the only way `(eg: the site uses its API to load the content, so scraping doesn't work)`.
|
|
||||||
|
|
||||||
Anyways, this guide won't teach the same concepts over and over again, <br/>
|
|
||||||
so if you can't even make requests to an API then this will not tell you how to do that.
|
|
||||||
|
|
||||||
Refer to [starting](../starting.md) on how to make http/https requests.
|
|
||||||
And yes, this guide expects you to have basic knowledge on both Python and Kotlin.
|
|
||||||
|
|
||||||
### Using an API (and parsing json)
|
|
||||||
So, the API I will use is the [SWAPI](https://swapi.dev/). <br/>
|
|
||||||
|
|
||||||
To parse that json data in python you would do:
|
|
||||||
```python
|
|
||||||
import requests
|
|
||||||
|
|
||||||
url = "https://swapi.dev/api/planets/1/"
|
|
||||||
json = requests.get(url).json()
|
|
||||||
|
|
||||||
""" What the variable json looks like
|
|
||||||
{
|
|
||||||
"name": "Tatooine",
|
|
||||||
"rotation_period": "23",
|
|
||||||
"orbital_period": "304",
|
|
||||||
"diameter": "10465",
|
|
||||||
"climate": "arid",
|
|
||||||
"gravity": "1 standard",
|
|
||||||
"terrain": "desert",
|
|
||||||
"surface_water": "1",
|
|
||||||
"population": "200000",
|
|
||||||
"residents": [
|
|
||||||
"https://swapi.dev/api/people/1/"
|
|
||||||
],
|
|
||||||
"films": [
|
|
||||||
"https://swapi.dev/api/films/1/"
|
|
||||||
],
|
|
||||||
"created": "2014-12-09T13:50:49.641000Z",
|
|
||||||
"edited": "2014-12-20T20:58:18.411000Z",
|
|
||||||
"url": "https://swapi.dev/api/planets/1/"
|
|
||||||
}
|
|
||||||
"""
|
|
||||||
```
|
|
||||||
Now, that is way too simple in python, sadly I am here to get your hopes down, and say that its not as simple in kotlin. <br/>
|
|
||||||
|
|
||||||
First of all, we are going to use a library named Jackson by FasterXML. <br/>
|
|
||||||
In build.gradle:
|
|
||||||
```gradle
|
|
||||||
repositories {
|
|
||||||
mavenCentral()
|
|
||||||
jcenter()
|
|
||||||
maven { url 'https://jitpack.io' }
|
|
||||||
}
|
|
||||||
|
|
||||||
dependencies {
|
|
||||||
...
|
|
||||||
...
|
|
||||||
implementation "com.fasterxml.jackson.module:jackson-module-kotlin:2.11.3"
|
|
||||||
compile group: 'khttp', name: 'khttp', version: '1.0.0'
|
|
||||||
}
|
|
||||||
```
|
|
||||||
After we have installed the dependencies needed, we have to define a schema for the json. <br/>
|
|
||||||
Essentially, we are going to write the structure of the json in order for jackson to parse our json. <br/>
|
|
||||||
This is an advantage for us, since it also means that we get the nice IDE autocomplete/suggestions and typehints! <br/><br/>
|
|
||||||
|
|
||||||
Getting the json data:
|
|
||||||
```kotlin
|
|
||||||
val jsonString = khttp.get("https://swapi.dev/api/planets/1/").text
|
|
||||||
```
|
|
||||||
|
|
||||||
First step is to build a mapper that reads the json string, in order to do that we need to import some things first.
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
import com.fasterxml.jackson.databind.DeserializationFeature
|
|
||||||
import com.fasterxml.jackson.module.kotlin.KotlinModule
|
|
||||||
import com.fasterxml.jackson.databind.json.JsonMapper
|
|
||||||
import com.fasterxml.jackson.module.kotlin.readValue
|
|
||||||
```
|
|
||||||
|
|
||||||
After that we initialize the mapper:
|
|
||||||
|
|
||||||
```kotlin
|
|
||||||
val mapper: JsonMapper = JsonMapper.builder().addModule(KotlinModule())
|
|
||||||
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false).build()
|
|
||||||
```
|
|
||||||
|
|
||||||
The next step is to...write down the structure of our json!
|
|
||||||
This is the boring part for some, but it can be automated by using websites like [json2kt](https://www.json2kt.com/) or [quicktype](https://app.quicktype.io/) to generate the entire code for you.
|
|
||||||
<br/><br/>
|
|
||||||
|
|
||||||
First step to declaring the structure for a json is to import the JsonProperty annotation.
|
|
||||||
```kotlin
|
|
||||||
import com.fasterxml.jackson.annotation.JsonProperty
|
|
||||||
```
|
|
||||||
Second step is to write down a data class that represents said json.
|
|
||||||
```kotlin
|
|
||||||
// example json = {"cat": "meow", "dog": ["w", "o", "o", "f"]}
|
|
||||||
|
|
||||||
data class Example (
|
|
||||||
@JsonProperty("cat") val cat: String,
|
|
||||||
@JsonProperty("dog") val dog: List<String>
|
|
||||||
)
|
|
||||||
```
|
|
||||||
This is as simple as it gets. <br/> <br/>
|
|
||||||
|
|
||||||
Enough of the examples, this is the representation of `https://swapi.dev/api/planets/1/` in kotlin:
|
|
||||||
```kotlin
|
|
||||||
data class Planet (
|
|
||||||
@JsonProperty("name") val name: String,
|
|
||||||
@JsonProperty("rotation_period") val rotationPeriod: String,
|
|
||||||
@JsonProperty("orbital_period") val orbitalPeriod: String,
|
|
||||||
@JsonProperty("diameter") val diameter: String,
|
|
||||||
@JsonProperty("climate") val climate: String,
|
|
||||||
@JsonProperty("gravity") val gravity: String,
|
|
||||||
@JsonProperty("terrain") val terrain: String,
|
|
||||||
@JsonProperty("surface_water") val surfaceWater: String,
|
|
||||||
@JsonProperty("population") val population: String,
|
|
||||||
@JsonProperty("residents") val residents: List<String>,
|
|
||||||
@JsonProperty("films") val films: List<String>,
|
|
||||||
@JsonProperty("created") val created: String,
|
|
||||||
@JsonProperty("edited") val edited: String,
|
|
||||||
@JsonProperty("url") val url: String
|
|
||||||
)
|
|
||||||
```
|
|
||||||
**For json that don't necessarily contain a key, or its type can be either the expected type or null, you need to write that type as nullable in the representation of that json.** <br/>
|
|
||||||
Example of the above situation:
|
|
||||||
```json
|
|
||||||
[
|
|
||||||
{
|
|
||||||
"cat":"meow"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"dog":"woof",
|
|
||||||
"cat":"meow"
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"fish":"meow",
|
|
||||||
"cat":"f"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
```
|
|
||||||
It's representation would be:
|
|
||||||
```kotlin
|
|
||||||
data class Example (
|
|
||||||
@JsonProperty("cat") val cat: String,
|
|
||||||
@JsonProperty("dog") val dog: String?,
|
|
||||||
@JsonProperty("fish") val fish: String?
|
|
||||||
)
|
|
||||||
```
|
|
||||||
As you can see, `dog` and `fish` are nullable because they are properties that are missing in an item. <br/>
|
|
||||||
Whilst `cat` is not nullable because it is available in all of the items. <br/>
|
|
||||||
Basic nullable detection is implemented in [json2kt](https://www.json2kt.com/) so its recommended to use that. <br/>
|
|
||||||
But it is very likely that it might fail to detect some nullable types, so it's up to us to validate the generated code.
|
|
||||||
|
|
||||||
Second step to parsing json is...to just call our `mapper` instance.
|
|
||||||
```kotlin
|
|
||||||
val json = mapper.readValue<Planet>(jsonString)
|
|
||||||
```
|
|
||||||
And voila! <br/>
|
|
||||||
We have successfully parsed our json within kotlin. <br/>
|
|
||||||
One thing to note is that you don't need to add all of the json key/value pairs to the structure, you can just have what you need.
|
|
||||||
|
|
||||||
### Note
|
|
||||||
Even though we set `DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES` as `false` it will still error on missing properties. <br/>
|
|
||||||
If a json may or may not include some info, make those properties as nullable in the structure you build.
|
|
||||||
|
|
||||||
### Next up: [Evading developer tools detection](../devtools_detectors.md)
|
|
||||||
|
|
@ -1,23 +0,0 @@
|
||||||
---
|
|
||||||
title: Using plugin template
|
|
||||||
parent: For extension developers
|
|
||||||
order: 1
|
|
||||||
---
|
|
||||||
|
|
||||||
# Using the template
|
|
||||||
The easiest way to start developing is to use our [plugin-template](https://github.com/recloudstream/plugin-template) as it sets up the build environment automatically.
|
|
||||||
|
|
||||||
1) <a href="https://github.com/recloudstream/plugin-template/generate" target="_blank">Use our plugin template</a>
|
|
||||||
|
|
||||||
2) Select `Include all branches`: <!-- -  -->
|
|
||||||
|
|
||||||
3) Check if GitHub actions are enabled, by going to: `Settings > Actions > General > Allow all actions and reusable workflows`
|
|
||||||
|
|
||||||
4) You can now create your own plugins and after you push new code, they should automatically be built
|
|
||||||
|
|
||||||
### Further reading
|
|
||||||
|
|
||||||
After you have set up the repository, you can continue by reading:
|
|
||||||
|
|
||||||
- [Creating your own JSON repository](../create-your-own-json-repository.md)
|
|
||||||
- [Creating your own providers](../create-your-own-providers.md)
|
|
||||||
|
|
@ -4,19 +4,33 @@ import Layout from "../../components/layout"
|
||||||
import DocsCard from "../../components/cards/docs"
|
import DocsCard from "../../components/cards/docs"
|
||||||
import SEO from "../../components/seo"
|
import SEO from "../../components/seo"
|
||||||
|
|
||||||
const DocsPage = () => {
|
const links = [
|
||||||
|
{
|
||||||
|
"url": "https://docs.cloudstream.cf/",
|
||||||
|
"name": "Docs",
|
||||||
|
"desc": "You will find all the help and information here."
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"url": "https://recloudstream.github.io/dokka/",
|
||||||
|
"name": "Dokka",
|
||||||
|
"desc": "Basically javadoc"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
|
||||||
|
const DocsPage = () => {
|
||||||
return <Layout>
|
return <Layout>
|
||||||
<div className="flex items-center w-full flex-col">
|
<div className="flex items-center w-full flex-col">
|
||||||
<article className="card bg-base-200 shadow-xl mx-10 mb-5 w-full md:w-2/3">
|
{links.map(it => (
|
||||||
<div className="card-body">
|
<article className="card bg-base-200 shadow-xl mx-10 mb-5 w-full md:w-2/3" key={it.url}>
|
||||||
<h2 className="card-title">Dokka</h2>
|
<div className="card-body">
|
||||||
<p>Basically javadoc</p>
|
<h2 className="card-title">{it.name}</h2>
|
||||||
<div className="card-actions justify-end">
|
<p>{it.desc}</p>
|
||||||
<a href="https://recloudstream.github.io/dokka/" className="btn btn-primary">View</a>
|
<div className="card-actions justify-end">
|
||||||
|
<a href={it.url} className="btn btn-primary">View</a>
|
||||||
|
</div>
|
||||||
</div>
|
</div>
|
||||||
</div>
|
</article>
|
||||||
</article>
|
))}
|
||||||
<StaticQuery
|
<StaticQuery
|
||||||
query={graphql`
|
query={graphql`
|
||||||
query {
|
query {
|
||||||
|
|
|
||||||
|
|
@ -1,34 +0,0 @@
|
||||||
---
|
|
||||||
title: Anime tracking FAQ
|
|
||||||
parent: For users
|
|
||||||
order: 7
|
|
||||||
---
|
|
||||||
|
|
||||||
# Anime tracking FAQ
|
|
||||||
|
|
||||||
Anime tracking process works with **only anime extensions**. So, it'll not work with extensions like superstream, sflix, loklok etc. Some anime extensions might also not work with the tracking process as the sources don't contain all the required metadata.
|
|
||||||
|
|
||||||
## Login Process
|
|
||||||
### Step 1
|
|
||||||
`Settings > Account >` **Choose AL or MAL**. For this guide we are choosing AL.
|
|
||||||

|
|
||||||
|
|
||||||
### Step 2
|
|
||||||
The app will forward to the default browser to login. Now **Login and authorize** the app. The site will return you the cloudstream app.
|
|
||||||

|
|
||||||

|
|
||||||
|
|
||||||
If the log in process is successful, you will see a pop text and there will be your profile picture at the top right section of the home and the settings page.
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
## Tracking
|
|
||||||
|
|
||||||
- When you go to the eps page of an anime, you will see the tracker icon (Logo of AL or MAL) at the top right corner. Click on that and you will see the tracking menu.
|
|
||||||

|
|
||||||
|
|
||||||
- The tracker will **automatically** track your anime after finishing the eps. Or you can **manually** input the number of eps you have watched.
|
|
||||||

|
|
||||||

|
|
||||||
|
|
||||||
- Also, the **status** of the anime and the **rating** can be set from the tracking menu
|
|
||||||
|
|
@ -1,44 +0,0 @@
|
||||||
---
|
|
||||||
title: FAQ
|
|
||||||
parent: For users
|
|
||||||
order: 1
|
|
||||||
---
|
|
||||||
|
|
||||||
## Can you add this site ....?
|
|
||||||
Yes, but we don't have infinite free time. Add the site in [#site-requests](https://discord.gg/5Hus6fM). We will not respond, but we will look at it when we feel like adding new sites. Adding sites properly takes hours and we do it for free.
|
|
||||||
Pinging developers will substantially decrease any chances of getting the site added. Adding the site yourself is the best way of getting it in the app.
|
|
||||||
|
|
||||||
## Site is not loading in the app, what to do?
|
|
||||||
1. Try the pre-release
|
|
||||||
2. Check that it loads in the browser
|
|
||||||
3. Try VPN & different DNS (Try both app DNS AND phone wide DNS in that order)
|
|
||||||
4. Report it if all of the above has failed
|
|
||||||
|
|
||||||
## Why is chromecasting not working?
|
|
||||||
If you can't start casting it's because the app doesn't find you TV on your network. VPN/Firewalls/wrong network may cause this.
|
|
||||||
|
|
||||||
If the videos won't load it's likely either due to:
|
|
||||||
The provider/video host simply not supporting casting (referer blocked), we can't fix this.
|
|
||||||
You are using a VPN, most video links are IP blocked meaning that casting will fail if you are connected to a VPN.
|
|
||||||
|
|
||||||
## Trailers.to keeps begging for a subscription
|
|
||||||
Check their site, if they are asking for a subscription it means that it doesn't exist on their site.
|
|
||||||
|
|
||||||
## When is imdb/trakt sync coming?
|
|
||||||
No ETA, but it's likely to come, by roughly that order.
|
|
||||||
|
|
||||||
## I am getting this error in the player: ...., what to do?
|
|
||||||
9 out of 10 times we can't help, don't report it, it's an error with exoplayer. If the same error is shown for all videos on a provider/source then do report it, it probably means the provider or source itself is outdated.
|
|
||||||
|
|
||||||
## Why is it buffering? I have great internet!
|
|
||||||
Because the server doesn't have as great internet, we can't fix, but you can:
|
|
||||||
1. Increase video cache
|
|
||||||
2. Try VPN (paradoxically it can speed up by improving routing)
|
|
||||||
|
|
||||||
## This app doesn't work on my TV!
|
|
||||||
If you are having issues navigating on your TV go to Settings > User interface > App layout > TV layout
|
|
||||||
|
|
||||||
If the issues persist after that report it
|
|
||||||
|
|
||||||
## How does it work ?
|
|
||||||
Basically this app sends requests to different websites (also called sources or providers) to find movies, series and animes and display them in the app nicely
|
|
||||||
|
|
@ -1,70 +0,0 @@
|
||||||
---
|
|
||||||
title: For users
|
|
||||||
parent: null
|
|
||||||
order: 1
|
|
||||||
---
|
|
||||||
|
|
||||||
# Cloudstream
|
|
||||||
An Android app to stream and download Movies, TV-Shows and Animes
|
|
||||||
This [open source app](https://github.com/recloudstream/cloudstream) can stream any media content from various sources
|
|
||||||
|
|
||||||
Check out the [FAQ](../faq.md) first!
|
|
||||||
|
|
||||||
Also check out [Troubleshooting](../troubleshooting.md) if you have any issues.
|
|
||||||
|
|
||||||
### Disclaimer ⚠️
|
|
||||||
The app is purely for educational and personal use.
|
|
||||||
|
|
||||||
CloudStream 3 does not host any content on the app, and has no control over what media is put up or taken down. CloudStream 3 functions like any other search engine, such as Google. CloudStream 3 does not host, upload or manage any videos, films or content. It simply crawls, aggregates and displayes links in a convenient, user-friendly interface.
|
|
||||||
|
|
||||||
It merely scrapes 3rd-party websites that are publicly accessible via any regular web browser.
|
|
||||||
|
|
||||||
It is the responsibility of the user to avoid any actions that might violate the laws governing his or her locality.
|
|
||||||
|
|
||||||
### What are the risks in practice?
|
|
||||||
Basically none. The content is hosted by the "providers", and if you don't distribute the content yourself, you are pretty much safe
|
|
||||||
|
|
||||||
A lot of misleading articles online try to scare people into buying a VPN subscription when the authors are earning a big commission (sometimes 100% of the VPN subscription).
|
|
||||||
VPNs are useful for certain things but aren't a magical tool and most people don't need those
|
|
||||||
|
|
||||||
## Features
|
|
||||||
|
|
||||||
### Streaming
|
|
||||||
|
|
||||||
You can stream media from various sources (developed by the community)
|
|
||||||
|
|
||||||
### Downloading
|
|
||||||
|
|
||||||
You can download media (movies, series and animes) files anywhere on your phone or external storage
|
|
||||||
|
|
||||||
### Searching
|
|
||||||
|
|
||||||
When you search for a media, Cloudstream will search every provider to see if it has that media or not.
|
|
||||||
|
|
||||||
You can change the list of used providers with the settings button in the search page
|
|
||||||
|
|
||||||
You can also enable foreign language providers (such as French) under:
|
|
||||||
|
|
||||||
Settings page > Provider Languages
|
|
||||||
|
|
||||||
and tick the ones you want there
|
|
||||||
|
|
||||||
### 100% free and no ads!
|
|
||||||
|
|
||||||
Cloudstream-3 (also refered to as Cs3) is open-source, that means that anyone can look at the code, there isn't any invasive data collection and anyone can create their own modifed version
|
|
||||||
|
|
||||||
This app doesn't contain any ads and is completely free to download, as a result this app doesn't make any money from someone using the app.
|
|
||||||
|
|
||||||
But you can still help it's development:
|
|
||||||
|
|
||||||
- By contributing to the code of the app itself (requires knowledge of Kotlin)
|
|
||||||
- By translating the app in another language
|
|
||||||
- By adding a star to the project on github
|
|
||||||
- By donating money to dependencies of the project (requires money) *The devs of Cloudstream-3 don't accept donations*
|
|
||||||
|
|
||||||
## Availability
|
|
||||||
You can download this app on Android, Android TV, and FireTV Stick. However, it is unfortunately not avaliable on IOS or on desktop, but you can use tools like:
|
|
||||||
- [WSA](https://docs.microsoft.com/en-us/windows/android/wsa/) on Windows
|
|
||||||
- [Waydroid](https://waydro.id/) or [Anbox](https://anbox.io/) on Linux
|
|
||||||
|
|
||||||
to emulate Android on desktop.
|
|
||||||
|
|
@ -1,27 +0,0 @@
|
||||||
---
|
|
||||||
title: Using local extensions
|
|
||||||
parent: For users
|
|
||||||
order: 3
|
|
||||||
---
|
|
||||||
|
|
||||||
It is possible to use extensions without using repositories. This can be useful when prototyping.
|
|
||||||
|
|
||||||
## To install an extension locally:
|
|
||||||
|
|
||||||
### 1. Give Cloudstream storage permissions
|
|
||||||
|
|
||||||
if you're using Android 11 or later you need to make sure that you **Allow management of all files**, not just media in the settings.
|
|
||||||
|
|
||||||
### 2. Start and close the app
|
|
||||||
|
|
||||||
If you've done everything correctly, you should now see a `Cloudstream3` folder in your device's files. Inside it there should be a `plugins` folder.
|
|
||||||
|
|
||||||
### 3. Download or compile extensions
|
|
||||||
|
|
||||||
You can now download (most likely from the `builds` branch of the repository of your choosing) or compile an extension. You should look for files ending with `.cs3`
|
|
||||||
|
|
||||||
### 4. Put your newly acquired `.cs3` file in the `Cloudstream3/plugins` folder.
|
|
||||||
|
|
||||||
### 5. You should now see your extension working.
|
|
||||||
|
|
||||||
You can make sure by going to `settings > extensions` and clicking the bottom progress bar to show a list of all extensions (including the locally installed ones)
|
|
||||||
|
|
@ -1,48 +0,0 @@
|
||||||
---
|
|
||||||
title: Subtitle Related FAQ
|
|
||||||
parent: For users
|
|
||||||
order: 6
|
|
||||||
---
|
|
||||||
|
|
||||||
## Subtitle appearance settings
|
|
||||||
`Settings> Player> Subtitles`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Subtitle sync
|
|
||||||
`Video player> Sync subs> Put your positive or negative delay`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Select subtitle source
|
|
||||||
`Video player> sources> subtitles>` 3 types of subtitle source:
|
|
||||||
- from the provider
|
|
||||||
- from the device
|
|
||||||
- from the internet which is [open subtitles](https://www.opensubtitles.com/)
|
|
||||||
|
|
||||||
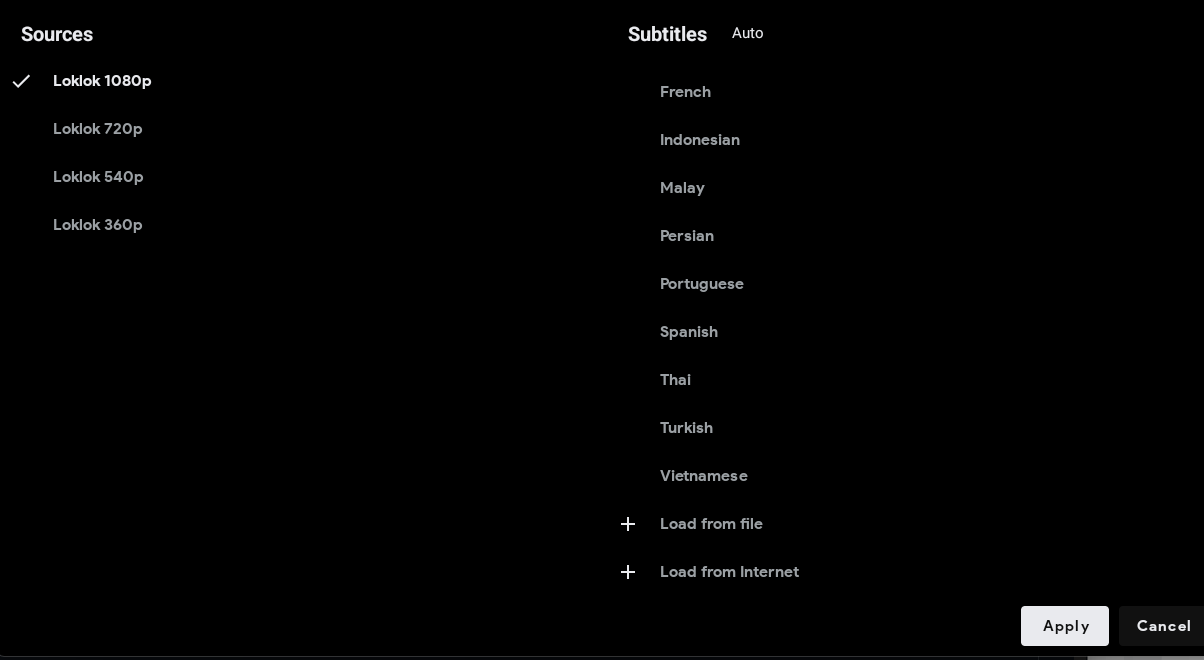
|
|
||||||
|
|
||||||
|
|
||||||
## How to use Open subtitles
|
|
||||||
`Settings> Account> OpenSubtitles>` Login with username and password
|
|
||||||
|
|
||||||
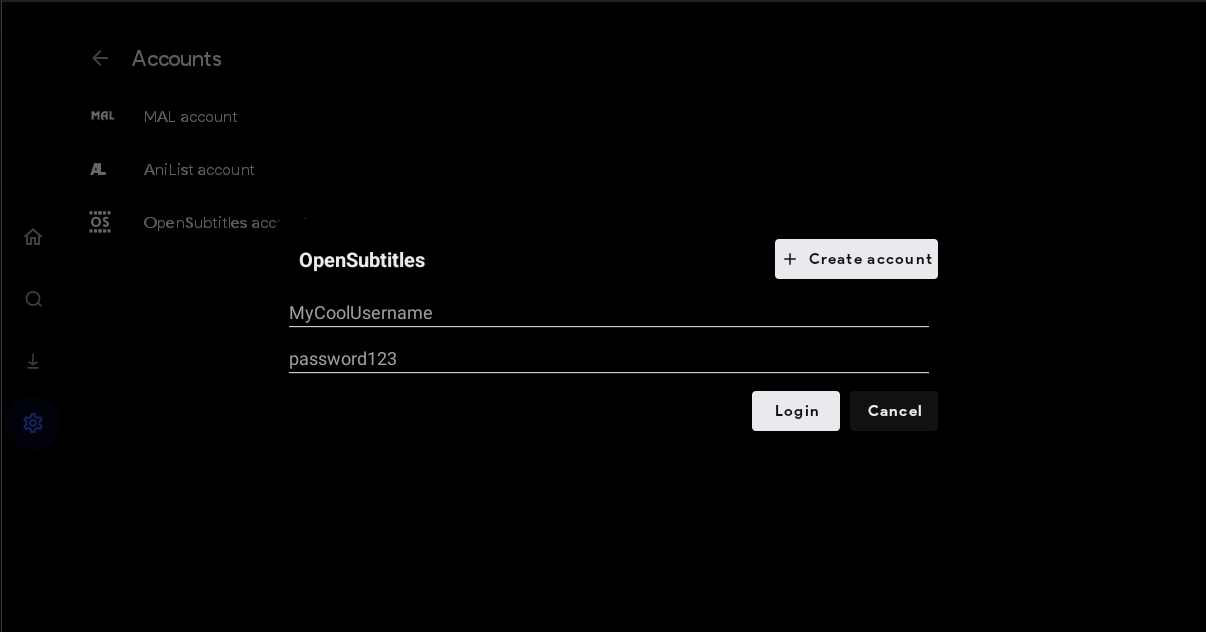
|
|
||||||
|
|
||||||
|
|
||||||
Or create an account [here](https://www.opensubtitles.com/en)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## How do I add my own subtitle
|
|
||||||
There are two ways you can add your own subtitle.
|
|
||||||
- From the device (`Video player> sources> subtitles> Load from file`)
|
|
||||||
- From the [Open substitles](https://www.opensubtitles.com/en/upload)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## How do I disable subtitles permanently
|
|
||||||
`Settings> Player> Subtitles> Auto-Select Language> None`
|
|
||||||
<video src="https://user-images.githubusercontent.com/57977673/194717490-0455d9f8-3b7d-4cb6-8148-c79ccf2c0c90.mp4" controls>
|
|
||||||
|
|
@ -1,26 +0,0 @@
|
||||||
---
|
|
||||||
title: How to use trakt list through stremio
|
|
||||||
parent: For users
|
|
||||||
order: 8
|
|
||||||
---
|
|
||||||
|
|
||||||
⚠ The Stremio extension is still experimental. Don't expect a stremio like experience. Most of the public stremio sources are torrent based but cloudstream doesn't support torrent stream. So, none of the popular sources will work here. The below trakt example is link only and it will not play any video. Also, this trakt doesn't sync anything.
|
|
||||||
|
|
||||||
1) Install the stremio extension from english repo.
|
|
||||||
|
|
||||||
2) Go to <a href="https://2ecbbd610840-trakt.baby-beamup.club/configure" target="_blank">this site</a>
|
|
||||||
|
|
||||||
3) Add the lists you want to see in the home section.
|
|
||||||
|
|
||||||
4) Click install
|
|
||||||
|
|
||||||
5) Copy the link address of the install button that appears again
|
|
||||||
|
|
||||||
6) Clone the stremio addon with the link you just pasted
|
|
||||||
|
|
||||||
7) At the start of the link, replace `stremio://` with `https://` and remove `manifest.json` from the end of the link
|
|
||||||
|
|
||||||
|
|
||||||
## Video guide
|
|
||||||
|
|
||||||
<div style="width: 100%; height: 0px; position: relative; padding-bottom: 56.250%;"><iframe src="https://streamable.com/e/wbrlnp" frameborder="0" width="100%" height="100%" allowfullscreen style="width: 100%; height: 100%; position: absolute;"></iframe></div>
|
|
||||||
|
|
@ -1,38 +0,0 @@
|
||||||
---
|
|
||||||
title: Troubleshooting CS3
|
|
||||||
parent: For users
|
|
||||||
order: 2
|
|
||||||
---
|
|
||||||
|
|
||||||
## Backup error
|
|
||||||
If you are unable to create a backup,
|
|
||||||
|
|
||||||
Change/reselect the download location.
|
|
||||||
`cs3 > settings > general > download path` and then select a custom location.
|
|
||||||
|
|
||||||
## Restore backup error
|
|
||||||
If you are unable to read the backup file,
|
|
||||||
|
|
||||||
Rename the extension of the file from `json to txt`.
|
|
||||||
Now try again to read the backup file.
|
|
||||||
|
|
||||||
## Error: Out of memory
|
|
||||||
If the movie doesn't play showing an error saying out of memory,
|
|
||||||
|
|
||||||
Change the video cache on disk
|
|
||||||
`cs3 > settings > player > video cache on disk` and set a **lower amount of cache**.
|
|
||||||
|
|
||||||
## Repositories are not loading in the official site
|
|
||||||
If the repositories are not loading in [this page](https://cloudstream.cf/repos/),
|
|
||||||
|
|
||||||
Try one of these solutions
|
|
||||||
- Turn on vpn and reload the page.
|
|
||||||
- Try the [rentry page](https://rentry.org/cs3/#repositories).
|
|
||||||
- Otherwise try the copy/type method
|
|
||||||
|
|
||||||
## Subtitle casting issue
|
|
||||||
If subtitle isn't casting on the tv with the native casting system,
|
|
||||||
|
|
||||||
Try casting using [this app](https://play.google.com/store/apps/details?id=com.instantbits.cast.webvideo).
|
|
||||||
`cs3 > eps page > press and hold the eps > play with Web Video Cast > choose the link` and then cast. *The subtitle selection maybe not as good as cs3.*
|
|
||||||
|
|
||||||
|
|
@ -1,133 +0,0 @@
|
||||||
---
|
|
||||||
title: How to use nginx with cloudstream
|
|
||||||
parent: For users
|
|
||||||
order: 4
|
|
||||||
---
|
|
||||||
|
|
||||||
## What is Nginx?
|
|
||||||
|
|
||||||
It's a free and open source software, it's really powerful but here we will only use it to display files on a simple web interface.
|
|
||||||
The files we are using will be media such as movies or animes, that you need to download yourself (here we will use torrents)
|
|
||||||
|
|
||||||
I will also refer to nginx as `HTTP access` in this tutorial because it allows the user to access his file using http.
|
|
||||||
|
|
||||||
**You must have a server (like a raspberry pi, a NAS or a seedbox) and a media collection to use this feature !**
|
|
||||||
|
|
||||||
### Why did I create that?
|
|
||||||
|
|
||||||
I used to be a user of [jellyfin](https://jellyfin.org/) because I didn't want to pay for a subscription and I didn't want to use proprietary software just to display files like plex.
|
|
||||||
It wasn't working really well and I sometimes wasn't able to play Movies and it semmed to use a lot of ressources
|
|
||||||
The solution? Scrape the media files and their metadata using Cloudstream-3
|
|
||||||
|
|
||||||
The advantages of this provier over jellyfin are that it's lightweight and integrated with cloudstream
|
|
||||||
|
|
||||||
**To setup nginx you must have a media server:**
|
|
||||||
- A 'managed' seedbox: is a service that you can rent and will take care of finding, downloading torrents and seeding them for you, check out mine [here](https://www.sarlays.com/my-media-server/), easiest method (that I use)
|
|
||||||
- You can also self host the media server, I cover the install of nginx [here](https://www.sarlays.com/unlisted/self-host-nginx) (harder)
|
|
||||||
|
|
||||||
Here I'll cover the install on a managed seedbox using ultra.cc
|
|
||||||
<!--
|
|
||||||
Here is a diagram I made to summarize how everything works:
|
|
||||||
|
|
||||||
```mermaid
|
|
||||||
flowchart TB
|
|
||||||
|
|
||||||
subgraph P[P2P network]
|
|
||||||
Alice((Alice)) <-- > Trackers
|
|
||||||
Bob((Bob)) <-- > Trackers
|
|
||||||
Paul((Paul)) <-- > Trackers
|
|
||||||
end
|
|
||||||
|
|
||||||
Trackers -- > Prowlarr
|
|
||||||
|
|
||||||
subgraph S[Search for Movies, Tv series, Animes]
|
|
||||||
Prowlarr <--- > |Requests| Radarr
|
|
||||||
Prowlarr <--- > |Requests| Sonarr
|
|
||||||
click Prowlarr callback "Prowlarr is used for stuff"
|
|
||||||
end
|
|
||||||
|
|
||||||
Sonarr -- > |Send torrent| A(Radarr)
|
|
||||||
Radarr[Radarr] -- > |Send torrent| A(Radarr)
|
|
||||||
A[Transmission] -- >|Download to filesystem| C{Nginx}
|
|
||||||
C -- >|Stream| D(Cloudstream-3)
|
|
||||||
|
|
||||||
|
|
||||||
Prowlarr is between the tracker and the media mangment apps (radarr and sonarr): it handles the requests to the trackers (that you add inside prowlarr)
|
|
||||||
``` -->
|
|
||||||
|
|
||||||
### What are trackers?
|
|
||||||
|
|
||||||
They are basically websites where you create an account and they "list" content hosted by other users registered on the website (they don't host the content themself).
|
|
||||||
Sonarr and radarr will then ask prowlarr to search for something specific like a movie or an anime inside this list built by the tracker
|
|
||||||
|
|
||||||
Once the movie is found, the torrent file is sent to transmission.
|
|
||||||
Transmission is basically a torrent downloader, it will download the files given by radarr and sonarr
|
|
||||||
|
|
||||||
### Installation with ultraseedbox
|
|
||||||
|
|
||||||
Ultraseedbox (now called ultra.cc) is a service that allows you to download torrents with really fast download speed and then seed those torrent (which means sharing it with other users how want to download them 24/7) but it cost some money, you can check them out [here](https://ultra.cc/) (I am not affiliated with them in any way, but their support and service is really great for me).
|
|
||||||
|
|
||||||
You can use any similar seedbox service that offers http access through nginx.
|
|
||||||
|
|
||||||
For my setup you have to install:
|
|
||||||
|
|
||||||
**required (for metadata):**
|
|
||||||
- Sonarr (for tv shows)
|
|
||||||
- Radarr (for movies)
|
|
||||||
- Nginx - http access (already installed by default on ultra.cc)
|
|
||||||
|
|
||||||
### Setting up radarr / sonarr
|
|
||||||
You must use a metadata downloader (that downloads `.nfo` files), I'll use radarr and sonarr since it's the easiest for me (it might be possible to download metadata using something else but I didn't try)
|
|
||||||
|
|
||||||
To install radarr and sonarr go into your control pannel, under installers search for sonarr and radarr
|
|
||||||
|
|
||||||
You now have to enable the download of metadata
|
|
||||||
|
|
||||||
To do so for Radarr go inside radarr to:
|
|
||||||
|
|
||||||
`settings > metadata`
|
|
||||||
|
|
||||||
you have to enable Kodi (XMBC) / Emby metadata
|
|
||||||
|
|
||||||
I use the following settings in radarr
|
|
||||||
|
|
||||||
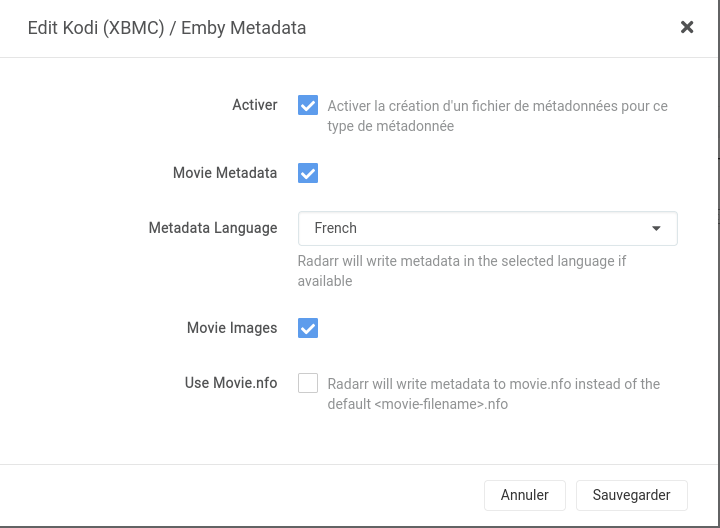
|
|
||||||
|
|
||||||
you must untick "use Movie.nfo" as shown in the screenshot
|
|
||||||
|
|
||||||
For Sonarr go to:
|
|
||||||
|
|
||||||
`settings > metadata`
|
|
||||||
|
|
||||||
And enable those settings
|
|
||||||
|
|
||||||
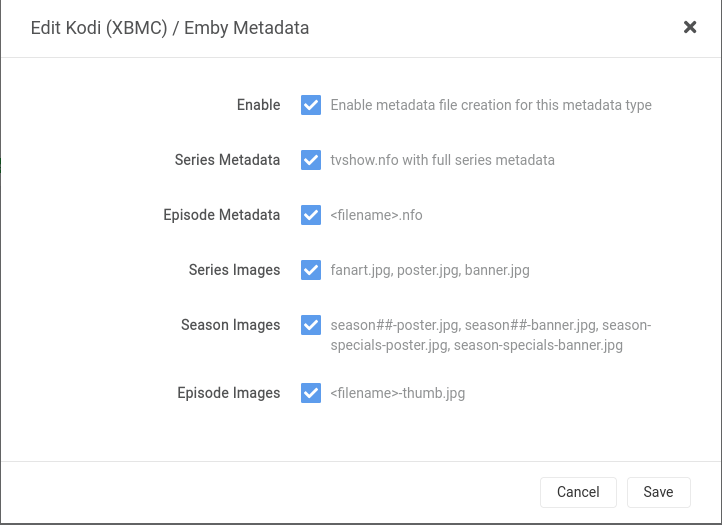
|
|
||||||
|
|
||||||
If the metadata is not present, the movie / tv show will not be displayed by cloudstream
|
|
||||||
|
|
||||||
Now we are ready, if you want to add folders to the http access you can follow the documentation coming from [ultra.cc](https://docs.usbx.me/books/http-access/page/downloading-files-from-your-ultracc-slot-using-http-access)
|
|
||||||
|
|
||||||
### In cloudstream
|
|
||||||
Go into the settings of Cloudstream-3 and click the Nginx server url button
|
|
||||||
|
|
||||||
Here you need to type the exact url of the http nginx server where you access your files, for exemple https://myusername.myles.usbx.me/
|
|
||||||
|
|
||||||
The http access requires authentification, you have to go under Nginx Credentials and type your username and password.
|
|
||||||
|
|
||||||
Those credentials are written in the control pannel of ultra.cc under:
|
|
||||||
|
|
||||||
`Access details > HTTP proxy access`
|
|
||||||
|
|
||||||
As written in the description, you have to supply those credentials using a very specific format,
|
|
||||||
let's say your username is `mycoolusername` and your password is `password1234` (Please use a password manager lol), then you have to type in the input: `mycoolusername:password1234`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
You now have to restart the app to apply the changes.
|
|
||||||
|
|
||||||
Nginx will now show up in the sources list on the home page
|
|
||||||
|
|
||||||
It might say that no url is supplied when starting the application, you can just hit the retry button and it should work fine
|
|
||||||
|
|
||||||
That's it, you added nginx to Cloudstream
|
|
||||||
|
|
@ -1,29 +0,0 @@
|
||||||
---
|
|
||||||
title: Installation on Windows 11
|
|
||||||
parent: For users
|
|
||||||
order: 5
|
|
||||||
---
|
|
||||||
|
|
||||||
## For Windows 11 users
|
|
||||||
|
|
||||||
- Download and install both of these pieces of software.
|
|
||||||
1. [Windows Subsystem for Android](https://apps.microsoft.com/store/detail/windows-subsystem-for-android%E2%84%A2-with-amazon-appstore/9P3395VX91NR?hl=en-us&gl=us)
|
|
||||||
2. [WSA Sideloader](https://github.com/infinitepower18/WSA-Sideloader) or [WSA Pacman](https://github.com/alesimula/wsa_pacman)
|
|
||||||
|
|
||||||
- Download the pre-release from [this site](https://recloudstream.github.io).
|
|
||||||
- Enable developer mode in WSA settings. It is also recommended you enable continuous mode, however WSA Sideloader will attempt to start the subsystem for you if it's not running.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
- Give the adb permission to install the apk. *(Make it allow always so that it will give less pain in the future.)*
|
|
||||||
|
|
||||||
If you're not in a supported country, change your PC region setting to United States, you should then be able to download Amazon Appstore which contains the subsystem. You can change it back once you have installed it.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
*Ref: [WSA Sideloader](https://github.com/infinitepower18/WSA-Sideloader)*
|
|
||||||
|
|
||||||
|
|
||||||
## Video guide
|
|
||||||
|
|
||||||
<video src="https://cdn.discordapp.com/attachments/737724143570780260/1031100838212538388/wsa.mp4" controls>
|
|
||||||
Loading…
Add table
Add a link
Reference in a new issue